Abstract
Large-scale dexterous grasp datasets encode rich priors over hand-object interaction, but their use has largely been confined to grasp generation and pick-and-place manipulation. We study whether such data can instead support functional dexterity in articulated tool use, where a robot must acquire a tool, maintain contact, and operate its functional moving parts. We adapt a hierarchical imitation learning framework that combines high-level hand sub-goal prediction with a low-level goal-conditioned controller. We construct a 355k-trajectory grasp-pretraining dataset from large-scale dexterous grasp annotations and use it to pretrain the low-level controller. The controller is then fine-tuned on downstream task demonstrations. To evaluate this setting, we introduce DexCraft, a simulation benchmark with six articulated tool-use tasks requiring coordinated finger motion. Across simulation and real-world experiments, our approach outperforms end-to-end diffusion policy baselines and hierarchical policies trained from scratch. In the real world, it improves full-task success by 33.3 percentage points over DP3. These results show that grasp datasets can serve not only as resources for grasp synthesis, but also as scalable pretraining data for contact-rich dexterous manipulation.
DexCraft Benchmark
We propose the DexCraft benchmark which contains six dexterous manipulation tasks. The robot hand is required to grasp the object, lift it to the target pose, and trigger the object's articulated joint.
We collect 5 demonstrations with human teleoperation and use MimicGen pipeline to augment to 100 demos.
Spray Bottle
Lighter
Dispenser
Pliers
Stapler
Pen
Real World Results (8x)
Syringe
Spray Bottle
Scissors
How did we achieve this?
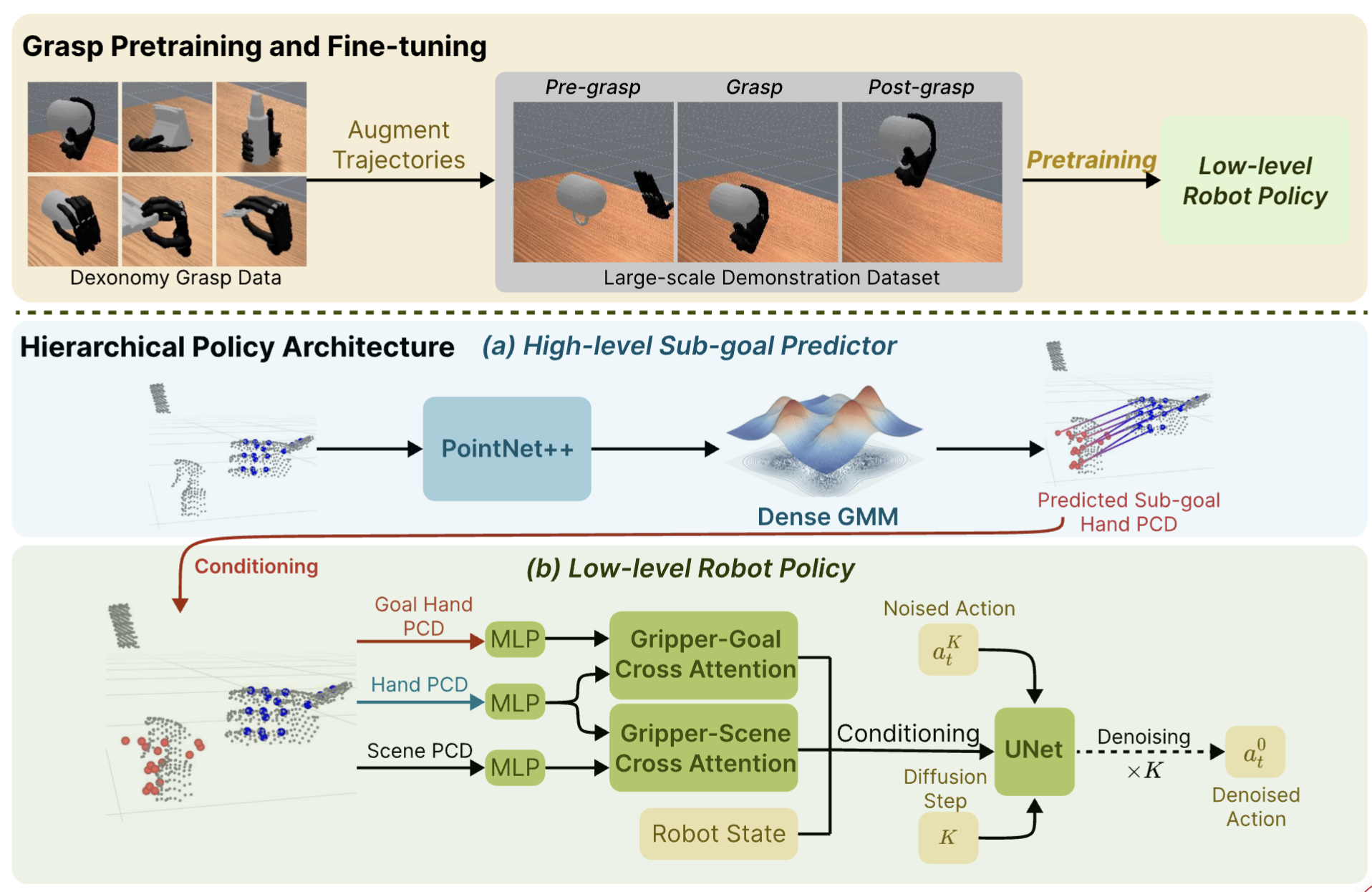
An overview of our approach. Our method integrates large-scale grasp pretraining with a hierarchical policy framework. (a) A high-level sub-goal prediction policy takes the current point cloud observation as input and predicts the positions of hand key points. (b) A low-level policy is conditioned on predicted sub-goal key points and current observation and predicts action chunks for the controller. Top: We augment the Dexonomy dataset into grasp trajectories and pretrain the low-level policy, which we fine-tune with data from the downstream task.
Visualization of G2D-Pretrain Dataset
We construct G2D-Pretrain, a large-scale dataset of 355k grasp trajectories by augmenting grasp annotations from Dexonomy.
High-level Prediction During Real-World Deployment
The following is a visualization of high-level policy prediction during real-world rollouts. Red points are goal hand points, blue points are current hand points, and grey points are scene points.
Qualitative Comparison in Simulation Tasks
DP3
Unstable grasp due to imprecise hand-object alignment.Hierarchical Policy from Scratch
Higher success rate than end-to-end policy, but still imperfect grasp in some cases.Our Method
Much more robust than baselines.Failure Cases (Baselines, 8x)
DP3
Grasp failure due to imprecise hand-object alignment.Hierarchical Policy from Scratch
Unstable grasp or failure in triggering the articulated component.Failure Cases (Our Method, 8x)
down the plunger before grasping.
knocks the object over.
leads to an unstable grasp.